最早的个性化学习源于孔子对子路和冉有的因材施教。我们可以说因材施教是在老师指点下进行的个性化学习。而信息化技术发展到今日,用人工智能代替真人教师进行指点,帮助学生进行个性化学习的学习方式,我们称之为自适应学习。
现阶段产生的自适应学习我们可以按照不同的实现水平划分不同的等级,最简单的自适应学习我们称为零级,其实就是真人教师判断与资源推送的组合。
在零级的自适应学习产品中,学生会发生学习行为,真人教师通过数据采集判断学习行为,推送学习资源。
例如:某英语自适应学习产品,学生在线提交自己的英语作文,真人教师在后台看到学生的作文内容并进行批改,找出学生的固定搭配的问题,语法问题,行文结构问题等进行批改。学生在收到老师的批改内容的同时也会收到相应的语法课,行文结构课。
这种自适应学习产品的算法逻辑很简单,真人教师把不同的问题类型和资源相关联,学生作文里只要出现某个问题就自动推送相应学习资源。
再举个例子:老师在线上一对一辅导数学,学生录入答案,老师发现学生的知识漏洞,除了可以推送课程,还可以选择推送不同难度的题目。
这种产品的逻辑也很简单,数学题有难度梯度,一道数学题可以由真人教师标记相关联的更高难度和更低难度的几道题,学生发生学习行为后,教师决定是加大难度还是减小难度还是进入下一个学习环节。
零级:由人工判断的自适应学习
当自适应学习产品运用电脑来做判断就进入了Ⅰ级自适应的范畴。
Ⅰ级自适应通过决策树做判断,不考虑学生行为是否代表知识的掌握程度,而是简单直接的判断学习行为对还是不对。
比如一些健身学习类软件,通过图像视频捕捉动作特征与自有的判断指标进行匹配,某个动作的某个角度超过标准,软件会提醒学生,你的动作不标准,腹部不够收紧,手臂高度不够等等。
不止是健身,各种球类运动,竞技体育,甚至乐器基本功都可以通过Ⅰ级自适应来学习。
Ⅰ级:基于简单规则的自适应学习
事实上除了带有硬性标准的学习任务,其他种类的学习判断是无法做到非对即错的。那么Ⅱ级自适应学习应该在简单的决策树之上建立更好的学习算法。
在Ⅱ级自适应学习中,不把学习行为的对错和某一个单一课程挂钩,而是建立一套完整的难度递增的课程,当学生学习行为完成度较好,提供大难度的课程,当学习行为完成度不高,就提供减少难度的课程,我们也可以称之为基于难度设计的自适应学习。
比如某知名辅导机构推出的大语文学习产品,使用了阅读分级。一个学生是否看懂一篇文章,原因有很多,可能是字的认识与否,可能是词语理解深度,可能是上下文的逻辑关系。国外认为阅读是存在等级的,不同真实年龄段的孩子可以通过阅读测试找到最合适他读的年龄段。通过不断的学习,学生可以阅读更高等级的材料。
Ⅱ级:基于难度等级的自适应学习
通过难度设计的自适应学习产品最大的问题是――认为学生学习是可以用一个难度值来掌握的,这样就像回归到传统的学校教学,把学生通过分班考试划到不同的班级,重点班和非重点班教授的内容和掌握程度是不一样的。这种学习形式本质上和学校教学没有太大差别,是任何一个比较用心的学校和教师都可以做到的因材施教。
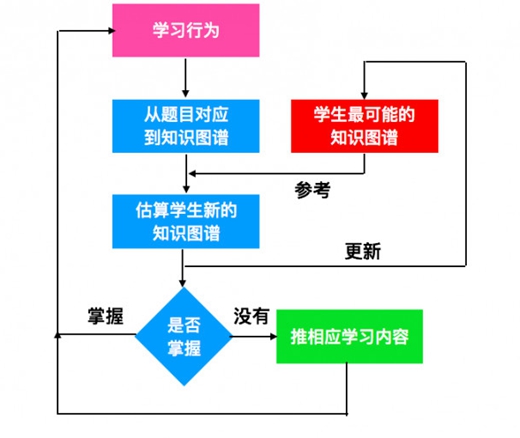
仅有难度等级无法关注到学科中的详细知识点掌握情况,因此Ⅲ级自适应需要用到知识图谱来衡量学科中细粒度的知识掌握情况。在Ⅲ级自适应中涉及到多个部分综合评定,我们一个一个来看。
Ⅲ级:基于知识点网络和概率模型的自适应学习
一、学习行为的可信度问题
假如两个同学做同一难度的一系列题目,并且这些题目都是只包含单一知识点的情况下,甲同学做了两道全对,正确率100%,乙同学做了20道,19道全对,正确率是95%。
从正确率上看,甲同学更高,但是由于他只做了两道题,可能是蒙对的,所以甲的学习行为的可信度是不如乙高的。因此,Ⅲ级自适应要考虑置信因子的问题。
二、单点不同难度题目评断问题
我们知道真实考试中,一个知识点可以有好多种不同难度的题目,题目的出题形式也是不一样的。
因此Ⅲ级自适应应该引入IRT(Item-response-theory)模型,考虑题目区分度,难度,可能性等多个因素综合评断。在此基础上利用深度学习的一系列算法,通过不断做题估算学生的真实情况。
三、一题对多点的问题
当一道题对应多个知识点又该怎么办呢。可以通过知识映射矩阵(qmatrix,以下简称为q矩阵)来解决。
Ⅲ级自适应学习系统搭建最大工作量就在q矩阵搭建上。前期需要大量人力为题目打标签,并且打标签的过程一定不能只是从狭义上的课本的章节知识点展开,还要涵盖做题策略,知识盲区,考察点,学生阅读理解能力是否过关等等。
四、知识关联形成图谱的问题
当q矩阵搭建起来以后,通过题目进行测试以后是可以将知识关联起来形成一个图谱。
我们发现从小到大的学习其实是一个知识不断被推翻的过程,也就是说高一形成的知识图谱,到高三相同的知识点关联起来的图谱可能完全不一样,甚至不同版本的教材会梳理出不同版本的知识图谱。那么输出图谱的健全性和可靠性就是一个比较大的问题。
五、变化的学习者的问题
随着学习行为的发生,学习者对于知识的掌握情况是会发生变化的。
举个例子:一个学生对某个数学知识点掌握程度适中,这个知识点的题目他做了20道,对了10道,真的代表他的正确率只有50%吗?不一定,有可能前10道题目他全做错了,但是在这个过程中他对知识点的掌握加深了,他学会了一些技巧和规律,后面10道全部做对了。
因此我们要以动态的视角看待学生。解决这个问题并不复杂,只需要将发生时间比较久远的行为数据权限变得低一些。除了这种情况,还有一种必须考虑的情况是,时间是会影响记忆的,随着时间的推移,学生遗忘知识的可能性会越来越高,这个问题大多数背单词软件已经利用spaced
repeatition算法解决。
综合以上的五个部分,Ⅲ级自适应学习已经做得较为精细,但是越精细带来人工成本越高。并且只能解决客观题,主观题自适应技术难度较大。
想要解决主观题自适应就进入到了Ⅳ级自适应,真正的AI级别的自适应。
这个水平的自适应学习产品可以将任何一道题目,通过NLP审题并转化成数学逻辑,再运用推理引擎得出正确答案,并且看到别人答案时,也可以分步骤精细判断答案是否正确,答案不正确时判断哪个步骤出现问题,进行适当点拨。Ⅳ级自适应产品的技术难点是“推理”。
目前没有哪个科技公司推出了真正的推理引擎,当下常见的扫题软件也只是识别问题再让学生抄答案而已,做不到真正有价值的点播和提醒。如果“推理”的技术难题攻克了,会让理科教师面临失业。给每一个学生配备一个AI教师,学生做题依然是采用纸笔方式,做题的同时AI老师会随时进行提醒和点拨,帮助学生快速成长和进步。
Ⅳ级:基于NLP和推理引擎的自适应学习
有一天Ⅳ级自适应出现了,前面几个级别的自适应会出现颠覆性改变。至于未来会不会出现更深层次的技术来改变现状,我们拭目以待吧。
本文来源:智慧课堂研究。
广州青鹿教育科技有限公司,智慧课堂整体解决方案提供商。这里有有趣的青鹿人,立志做好的智慧课堂,挖掘新鲜的教育资讯,分享你关注的热点话题。欢迎关注公众号:青鹿教育(ID:qljy_2017)